\n
## Violin Plot: US Foreign Policy Accuracy
### Overview
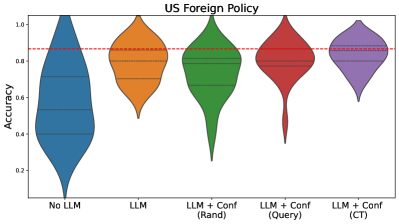
The image presents a violin plot comparing the accuracy of different approaches related to Large Language Models (LLMs) in the context of US Foreign Policy. The x-axis represents the different approaches, and the y-axis represents the accuracy. A horizontal dashed red line is present across all violin plots, likely representing a baseline or threshold.
### Components/Axes
* **Title:** "US Foreign Policy" (centered at the top)
* **Y-axis Label:** "Accuracy" (left side) - Scale ranges from approximately 0.2 to 1.0, with markings at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Labels:**
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Horizontal Line:** A dashed red line at approximately y = 0.8.
* **Violin Plots:** Five violin plots, each representing a different approach. The colors are:
* "No LLM": Blue
* "LLM": Orange
* "LLM + Conf (Rand)": Green
* "LLM + Conf (Query)": Red
* "LLM + Conf (CT)": Purple
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each approach. The width of each violin represents the density of data points at each accuracy level.
* **No LLM (Blue):** The distribution is relatively wide, ranging from approximately 0.2 to 1.0, with a peak around 0.6. The plot is somewhat skewed to the left.
* **LLM (Orange):** The distribution is centered around 0.6-0.7, with a range of approximately 0.4 to 0.9. It's less wide than the "No LLM" plot.
* **LLM + Conf (Rand) (Green):** This plot shows a distribution centered around 0.8-0.9, with a range of approximately 0.6 to 1.0. It appears to have a higher median accuracy than the previous two.
* **LLM + Conf (Query) (Red):** The distribution is centered around 0.6-0.7, with a range of approximately 0.4 to 0.9. It is similar to the LLM plot, but slightly more spread out.
* **LLM + Conf (CT) (Purple):** The distribution is centered around 0.8-0.9, with a range of approximately 0.6 to 1.0. It is similar to the "LLM + Conf (Rand)" plot.
The dashed red line at approximately 0.8 appears to be a benchmark. The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches have a significant portion of their distributions above this line.
### Key Observations
* The "No LLM" approach has the widest distribution of accuracy scores, suggesting the most variability.
* Adding an LLM generally improves accuracy compared to "No LLM".
* The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches consistently achieve the highest accuracy scores, with a substantial portion of their distributions exceeding the 0.8 benchmark.
* The "LLM + Conf (Query)" approach does not show a significant improvement over the basic "LLM" approach.
### Interpretation
The data suggests that incorporating LLMs, particularly when combined with confidence measures using either a random or CT method, significantly improves accuracy in the context of US Foreign Policy analysis. The "No LLM" approach demonstrates the highest variability, indicating a lack of consistent performance. The horizontal red line likely represents a desired level of accuracy, and the "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches are most likely to meet or exceed this threshold. The "LLM + Conf (Query)" approach's performance is comparable to the basic LLM approach, suggesting that the query-based confidence method may not be as effective as the other two. This could be due to the nature of the queries used or the specific confidence calculation method. The violin plots provide a clear visualization of the distribution of accuracy scores, allowing for a nuanced understanding of the performance of each approach.