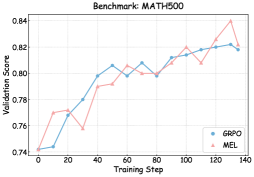
## Line Graph: Benchmark MATH500 Validation Scores
### Overview
The image shows a line graph comparing the validation scores of two models (GRPO and MEL) across training steps on the MATH500 benchmark. The graph spans 140 training steps with validation scores ranging from 0.74 to 0.84.
### Components/Axes
- **X-axis**: Training Step (0 to 140, increments of 20)
- **Y-axis**: Validation Score (0.74 to 0.84, increments of 0.02)
- **Legend**:
- Blue line: GRPO
- Red line: MEL
- **Title**: "Benchmark: MATH500" (top center)
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at (0, 0.74)
- Gradual upward trend with minor fluctuations
- Key points:
- (20, 0.77)
- (40, 0.795)
- (60, 0.80)
- (80, 0.80)
- (100, 0.815)
- (120, 0.82)
- (140, 0.82)
2. **MEL (Red Line)**:
- Starts at (0, 0.74)
- More volatile with sharp rises and dips
- Key points:
- (20, 0.77)
- (30, 0.76)
- (40, 0.79)
- (50, 0.805)
- (60, 0.81)
- (70, 0.80)
- (80, 0.80)
- (90, 0.81)
- (100, 0.82)
- (110, 0.81)
- (120, 0.84)
- (140, 0.82)
### Key Observations
1. Both models start at identical validation scores (0.74) at step 0.
2. MEL shows higher volatility, with a notable dip to 0.76 at step 30 and a peak of 0.84 at step 120.
3. GRPO demonstrates steadier growth, maintaining a consistent upward trajectory.
4. Both models converge at step 80 with identical scores (0.80).
5. MEL achieves the highest validation score (0.84) at step 120 but drops to 0.82 by step 140.
6. GRPO maintains a stable score of 0.82 from step 120 onward.
### Interpretation
The data suggests:
- **MEL** may have higher potential peak performance (0.84) but with instability, as evidenced by its fluctuations and post-peak decline.
- **GRPO** shows more reliable and consistent improvement, maintaining a stable 0.82 score after step 100.
- The convergence at step 80 indicates both models achieve similar baseline performance by mid-training.
- MEL's late-stage peak (step 120) might indicate overfitting or a temporary performance boost, given its subsequent drop.
The graph highlights a trade-off between stability (GRPO) and potential high performance with risk (MEL) in model training dynamics.