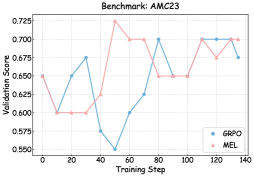
## Line Graph: Benchmark AMC23 Performance Comparison
### Overview
The image displays a line graph comparing the validation scores of two models (GRPO and MEL) across 140 training steps. The graph shows fluctuating performance metrics with notable volatility in both series.
### Components/Axes
- **X-axis**: "Training Step" (0 to 140, increments of 20)
- **Y-axis**: "Validation Score" (0.550 to 0.725, increments of 0.025)
- **Legend**: Located in bottom-right corner
- Blue line: GRPO
- Pink line: MEL
- **Title**: "Benchmark: AMC23" (top-center)
### Detailed Analysis
1. **GRPO (Blue Line)**:
- Starts at 0.65 (step 0)
- Dips to 0.55 at step 40 (lowest point)
- Peaks at 0.70 at step 80
- Ends at 0.675 (step 140)
- Shows significant volatility with sharp rises/falling patterns
2. **MEL (Pink Line)**:
- Starts at 0.65 (step 0)
- Drops to 0.60 at step 20
- Spikes to 0.725 at step 40 (highest point)
- Stabilizes around 0.70 after step 100
- Ends at 0.70 (step 140)
- Exhibits more pronounced early fluctuations
### Key Observations
- Both models show **high volatility** in early training steps (0-60)
- **GRPO** demonstrates a **U-shaped pattern** with a trough at step 40
- **MEL** exhibits a **peak-valley-peak pattern** with maximum performance at step 40
- After step 100, both lines **converge** toward similar performance levels
- **Notable outlier**: MEL's spike to 0.725 at step 40 exceeds GRPO's maximum by 0.025
### Interpretation
The graph suggests:
1. **Initial Performance Divergence**: MEL shows stronger early gains but experiences a sharp decline after step 40, while GRPO maintains more consistent growth until step 80.
2. **Stabilization Phase**: Both models converge toward similar performance levels in later training steps, indicating potential equilibrium in their learning trajectories.
3. **Volatility Implications**: The pronounced fluctuations suggest possible overfitting risks or model sensitivity to hyperparameters during early training phases.
4. **Benchmark Context**: The AMC23 benchmark appears to test models' ability to maintain performance under varying training conditions, with both approaches showing comparable final effectiveness despite different learning curves.
The data implies that while MEL may offer short-term advantages, GRPO demonstrates better long-term stability. Further analysis would be needed to determine optimal training duration and model selection criteria for this specific benchmark.