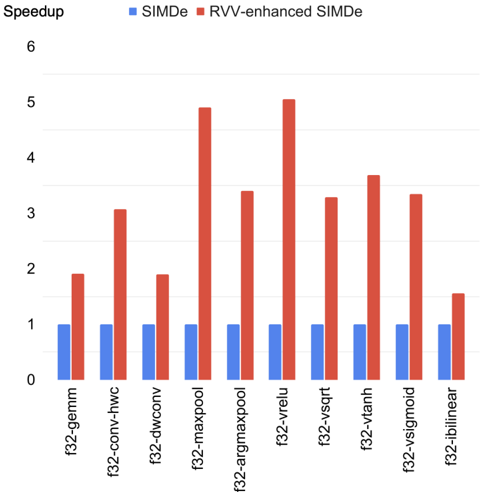
## Bar Chart: Speedup Comparison of SIMDe vs. RVV-enhanced SIMDe
### Overview
This bar chart compares the speedup achieved by two methods: SIMDe (Single Instruction Multiple Data extension) and RVV-enhanced SIMDe (Radeon Vector Vision enhanced SIMDe) across various operations. The chart displays the speedup factor for each operation, with bars representing the performance of each method.
### Components/Axes
* **Y-axis:** "Speedup" ranging from 0 to 6, with tick marks at intervals of 1.
* **X-axis:** Represents different operations: "f32-gemm", "f32-conv-hwc", "f32-dconv", "f32-maxpool", "f32-argmaxpool", "f32-vrelu", "f32-vsqrt", "f32-vtanh", "f32-vsigmoid", "f32-ibilinear".
* **Legend:** Located at the top-left corner, distinguishing between "SIMDe" (represented by blue bars) and "RVV-enhanced SIMDe" (represented by red bars).
### Detailed Analysis
The chart consists of paired bars for each operation, one blue (SIMDe) and one red (RVV-enhanced SIMDe).
* **f32-gemm:** SIMDe speedup is approximately 0.8. RVV-enhanced SIMDe speedup is approximately 2.1.
* **f32-conv-hwc:** SIMDe speedup is approximately 1.1. RVV-enhanced SIMDe speedup is approximately 3.4.
* **f32-dconv:** SIMDe speedup is approximately 0.9. RVV-enhanced SIMDe speedup is approximately 2.0.
* **f32-maxpool:** SIMDe speedup is approximately 0.7. RVV-enhanced SIMDe speedup is approximately 4.8.
* **f32-argmaxpool:** SIMDe speedup is approximately 1.0. RVV-enhanced SIMDe speedup is approximately 3.5.
* **f32-vrelu:** SIMDe speedup is approximately 1.2. RVV-enhanced SIMDe speedup is approximately 5.2.
* **f32-vsqrt:** SIMDe speedup is approximately 1.1. RVV-enhanced SIMDe speedup is approximately 3.7.
* **f32-vtanh:** SIMDe speedup is approximately 1.2. RVV-enhanced SIMDe speedup is approximately 3.9.
* **f32-vsigmoid:** SIMDe speedup is approximately 1.0. RVV-enhanced SIMDe speedup is approximately 3.4.
* **f32-ibilinear:** SIMDe speedup is approximately 1.1. RVV-enhanced SIMDe speedup is approximately 2.2.
For all operations, the RVV-enhanced SIMDe consistently demonstrates a higher speedup than the standard SIMDe.
### Key Observations
* The largest speedup difference between the two methods is observed in "f32-vrelu" (RVV-enhanced SIMDe speedup of ~5.2 vs. SIMDe speedup of ~1.2).
* The smallest speedup difference is observed in "f32-gemm" (RVV-enhanced SIMDe speedup of ~2.1 vs. SIMDe speedup of ~0.8).
* SIMDe speedups generally range between 0.7 and 1.2.
* RVV-enhanced SIMDe speedups generally range between 2.0 and 5.2.
### Interpretation
The data strongly suggests that incorporating Radeon Vector Vision (RVV) significantly enhances the performance of SIMDe operations. The consistent and substantial speedups across all tested operations indicate that RVV is an effective optimization for these types of computations. The variation in speedup across different operations suggests that the benefits of RVV may be more pronounced for certain operations (like "f32-vrelu") than others (like "f32-gemm"). This could be due to the specific characteristics of each operation and how well they align with the RVV architecture. The chart provides compelling evidence for the advantages of using RVV-enhanced SIMDe for improved computational efficiency.