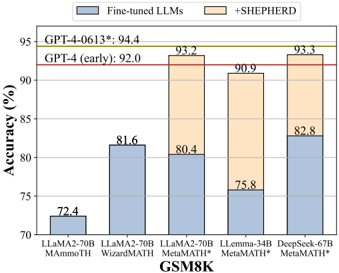
## Bar Chart: LLM Accuracy on GSM8K Dataset
### Overview
This bar chart compares the accuracy of several Large Language Models (LLMs) on the GSM8K dataset, a benchmark for mathematical problem-solving. The chart shows the accuracy of the models in their fine-tuned state and when augmented with the "+SHEPHERD" method. Two horizontal lines indicate the accuracy of GPT-4 models (early and a later version).
### Components/Axes
* **X-axis:** LLM Models - LLaMA2-70B (AMMO TH), LLaMA2-70B (WizardMATH), LLaMA2-70B (MetaMATH), LLemma-34B (MetaMATH), DeepSeek-67B (MetaMATH).
* **Y-axis:** Accuracy (%) - Scale ranges from 70% to 95%. Gridlines are present at 5% intervals.
* **Legend:**
* Gray: Fine-tuned LLMs
* Orange: +SHEPHERD
* **Horizontal Lines:**
* GPT-4-0613*: 94.4%
* GPT-4 (early): 92.0%
* **Title:** GSM8K (located along the x-axis)
### Detailed Analysis
The chart consists of five sets of paired bars, each representing a different LLM. The left bar in each pair represents the accuracy of the fine-tuned LLM, and the right bar represents the accuracy when using the "+SHEPHERD" method.
* **LLaMA2-70B (AMMO TH):**
* Fine-tuned: Approximately 72.4%
* +SHEPHERD: Not applicable (only one bar present)
* **LLaMA2-70B (WizardMATH):**
* Fine-tuned: Approximately 81.6%
* +SHEPHERD: Not applicable (only one bar present)
* **LLaMA2-70B (MetaMATH):**
* Fine-tuned: Approximately 80.4%
* +SHEPHERD: Approximately 93.2%
* **LLemma-34B (MetaMATH):**
* Fine-tuned: Approximately 75.8%
* +SHEPHERD: Approximately 90.9%
* **DeepSeek-67B (MetaMATH):**
* Fine-tuned: Approximately 82.8%
* +SHEPHERD: Approximately 93.3%
The horizontal lines representing GPT-4's accuracy are positioned at 92.0% (GPT-4 early) and 94.4% (GPT-4-0613*).
### Key Observations
* The "+SHEPHERD" method consistently improves the accuracy of the LLMs.
* LLaMA2-70B (MetaMATH), LLemma-34B (MetaMATH), and DeepSeek-67B (MetaMATH) with "+SHEPHERD" achieve accuracy levels comparable to or exceeding the earlier version of GPT-4.
* LLaMA2-70B (AMMO TH) and LLaMA2-70B (WizardMATH) have significantly lower accuracy compared to the other models, even with fine-tuning.
* The largest performance gain from "+SHEPHERD" is observed with LLaMA2-70B (MetaMATH), increasing accuracy by approximately 12.8 percentage points.
### Interpretation
The data suggests that the "+SHEPHERD" method is a highly effective technique for improving the mathematical problem-solving capabilities of LLMs. The substantial accuracy gains observed across multiple models indicate that "+SHEPHERD" provides a significant boost to performance on the GSM8K dataset. The fact that some models, when combined with "+SHEPHERD", reach or surpass the accuracy of GPT-4 (early) is particularly noteworthy, suggesting that these models can be competitive with state-of-the-art performance with the right augmentation. The varying levels of improvement across different models suggest that the effectiveness of "+SHEPHERD" may depend on the underlying architecture and training data of the LLM. The lower performance of LLaMA2-70B (AMMO TH) and LLaMA2-70B (WizardMATH) may indicate that these models are less well-suited for mathematical reasoning tasks, or that their fine-tuning process was less effective. The consistent improvement across the other models suggests a generalizable benefit from the "+SHEPHERD" approach.