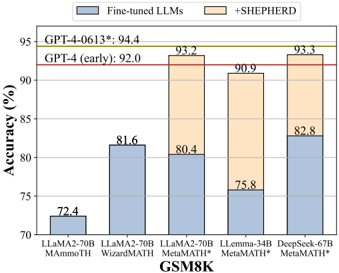
## Bar Chart: Model Accuracy Comparison on GSM8K Dataset
### Overview
This is a grouped bar chart comparing the accuracy percentages of five different large language models (LLMs) on the GSM8K mathematical reasoning benchmark. Each model is evaluated under two conditions: as a "Fine-tuned LLM" (blue bars) and with the addition of "+SHEPHERD" (orange bars). Two horizontal red lines provide performance benchmarks for GPT-4 models.
### Components/Axes
* **Chart Type:** Grouped vertical bar chart.
* **Y-Axis:** Labeled "Accuracy (%)". Scale ranges from 70 to 95, with major tick marks every 5 units (70, 75, 80, 85, 90, 95).
* **X-Axis:** Labeled "GSM8K". It lists five distinct model configurations:
1. `LLaMA2-70b MAMoTH`
2. `LLaMA2-70b WizardMATH`
3. `LLaMA2-70b MetaMath*`
4. `LLaMA-34b MetaMath*`
5. `DeepSeek-67b MetaMath*`
* **Legend:** Positioned at the top center of the chart area.
* A blue square corresponds to the label "Fine-tuned LLMs".
* An orange square corresponds to the label "+SHEPHERD".
* **Benchmark Lines:** Two solid red horizontal lines span the chart width.
* The upper line is labeled `GPT-4-0613*: 94.4` at its left end.
* The lower line is labeled `GPT-4 (early): 92.0` at its left end.
### Detailed Analysis
The chart presents paired data for each of the five models. The blue bar represents the baseline fine-tuned model's accuracy, and the orange bar represents the accuracy after applying the SHEPHERD method.
1. **LLaMA2-70b MAMoTH:**
* Fine-tuned LLMs (Blue): 72.4%
* +SHEPHERD (Orange): 81.6%
* **Trend:** A significant upward increase of approximately 9.2 percentage points.
2. **LLaMA2-70b WizardMATH:**
* Fine-tuned LLMs (Blue): 81.6%
* +SHEPHERD (Orange): 93.2%
* **Trend:** A substantial upward increase of approximately 11.6 percentage points.
3. **LLaMA2-70b MetaMath*:**
* Fine-tuned LLMs (Blue): 80.4%
* +SHEPHERD (Orange): 90.9%
* **Trend:** A strong upward increase of approximately 10.5 percentage points.
4. **LLaMA-34b MetaMath*:**
* Fine-tuned LLMs (Blue): 75.8%
* +SHEPHERD (Orange): 90.9%
* **Trend:** A very large upward increase of approximately 15.1 percentage points.
5. **DeepSeek-67b MetaMath*:**
* Fine-tuned LLMs (Blue): 82.8%
* +SHEPHERD (Orange): 93.3%
* **Trend:** A strong upward increase of approximately 10.5 percentage points.
**Benchmark Comparison:**
* The `GPT-4 (early)` benchmark is at 92.0%.
* The `GPT-4-0613*` benchmark is at 94.4%.
* With SHEPHERD, three models (LLaMA2-70b WizardMATH, LLaMA2-70b MetaMath*, DeepSeek-67b MetaMath*) achieve accuracy at or above the `GPT-4 (early)` benchmark.
* The highest performing model configuration is `DeepSeek-67b MetaMath* +SHEPHERD` at 93.3%, which is 1.1 percentage points below the `GPT-4-0613*` benchmark.
### Key Observations
1. **Universal Improvement:** The addition of SHEPHERD results in a consistent and substantial accuracy improvement for every single model tested. The improvement ranges from ~9.2 to ~15.1 percentage points.
2. **Performance Tier:** The SHEPHERD-enhanced models cluster in a high-performance tier between 90.9% and 93.3%, while the baseline fine-tuned models are more spread out between 72.4% and 82.8%.
3. **Model Comparison:** Among the baseline fine-tuned models, `DeepSeek-67b MetaMath*` (82.8%) and `LLaMA2-70b WizardMATH` (81.6%) perform best. With SHEPHERD, `DeepSeek-67b MetaMath*` (93.3%) and `LLaMA2-70b WizardMATH` (93.2%) remain the top performers.
4. **Benchmark Proximity:** The SHEPHERD method enables several open-weight models to reach performance levels competitive with early and mid-2023 versions of a leading proprietary model (GPT-4).
### Interpretation
This chart demonstrates the potent effect of the SHEPHERD technique as a performance multiplier for fine-tuned LLMs on mathematical reasoning tasks. The data suggests that SHEPHERD is not merely an incremental improvement but a transformative one, consistently bridging a significant portion of the gap between various fine-tuned models and the GPT-4 benchmark.
The fact that models of different sizes (34b, 67b, 70b) and from different fine-tuning families (MAMoTH, WizardMATH, MetaMath*) all show dramatic gains indicates that SHEPHERD likely addresses a fundamental limitation in the reasoning or problem-solving process of the base fine-tuned models, rather than being a narrow fix for a specific model architecture.
The narrowing of the performance spread among the SHEPHERD-enhanced models (90.9% - 93.3%) compared to the baselines (72.4% - 82.8%) implies that the technique may help models converge toward a higher performance ceiling on this benchmark, potentially by instilling a more robust and generalizable reasoning methodology. The results position SHEPHERD as a highly valuable method for elevating the capabilities of open-weight models to compete with state-of-the-art proprietary systems on complex reasoning benchmarks.