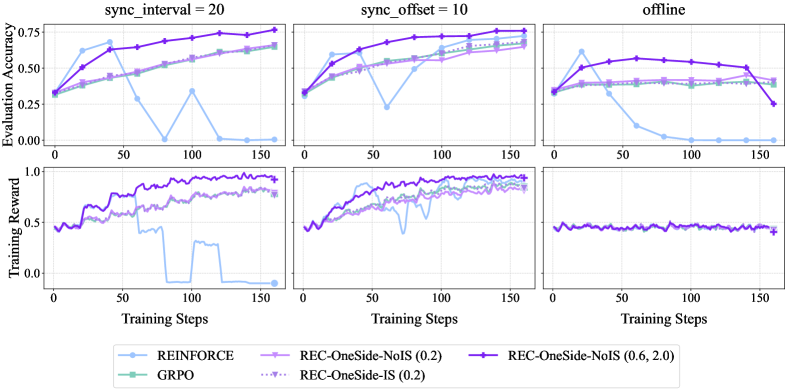
\n
## Multi-Panel Line Chart: Comparative Performance of Reinforcement Learning Algorithms
### Overview
The image displays a 2x3 grid of line charts comparing the performance of five different reinforcement learning algorithms across three distinct experimental conditions. The top row tracks "Evaluation Accuracy" over training steps, while the bottom row tracks "Training Reward". The three columns represent different synchronization settings: "sync_interval = 20", "sync_offset = 10", and "offline".
### Components/Axes
* **Main Titles (Column Headers):** "sync_interval = 20", "sync_offset = 10", "offline".
* **Y-Axis Labels (Row Headers):**
* Top Row: "Evaluation Accuracy" (Scale: 0.00 to 0.75, with ticks at 0.00, 0.25, 0.50, 0.75).
* Bottom Row: "Training Reward" (Scale: 0.0 to 1.0, with ticks at 0.0, 0.5, 1.0).
* **X-Axis Label (Common to all plots):** "Training Steps" (Scale: 0 to 150, with ticks at 0, 50, 100, 150).
* **Legend (Bottom Center):** Contains five entries, each with a distinct color and marker:
1. `REINFORCE` - Light blue line with circle markers.
2. `GRPO` - Teal line with square markers.
3. `REC-OneSide-NoIS (0.2)` - Light purple line with diamond markers.
4. `REC-OneSide-IS (0.2)` - Dotted purple line with upward-pointing triangle markers.
5. `REC-OneSide-NoIS (0.6, 2.0)` - Dark purple line with plus (+) markers.
### Detailed Analysis
**Top Row: Evaluation Accuracy**
* **sync_interval = 20 (Top-Left Plot):**
* `REC-OneSide-NoIS (0.6, 2.0)` (Dark purple, +): Shows a strong, steady upward trend from ~0.35 at step 0 to ~0.75 at step 150. It is the top-performing algorithm.
* `GRPO` (Teal, square): Increases steadily from ~0.35 to ~0.65.
* `REC-OneSide-NoIS (0.2)` (Light purple, diamond) & `REC-OneSide-IS (0.2)` (Dotted purple, triangle): Both show similar, moderate upward trends, ending near ~0.65.
* `REINFORCE` (Light blue, circle): Highly unstable. Starts near 0.35, peaks at ~0.65 around step 40, then crashes to near 0.00 by step 75, with a brief recovery spike before falling again.
* **sync_offset = 10 (Top-Middle Plot):**
* `REC-OneSide-NoIS (0.6, 2.0)` (Dark purple, +): Again shows a strong upward trend, reaching ~0.75.
* `GRPO`, `REC-OneSide-NoIS (0.2)`, `REC-OneSide-IS (0.2)`: All cluster together, showing steady improvement to ~0.65-0.70.
* `REINFORCE` (Light blue, circle): Exhibits a sharp dip to ~0.25 around step 60 but recovers to join the cluster near ~0.65 by step 150.
* **offline (Top-Right Plot):**
* `REC-OneSide-NoIS (0.6, 2.0)` (Dark purple, +): Increases to a peak of ~0.60 around step 100, then declines to ~0.25 by step 150.
* `GRPO`, `REC-OneSide-NoIS (0.2)`, `REC-OneSide-IS (0.2)`: All plateau early around ~0.40-0.50 and remain flat.
* `REINFORCE` (Light blue, circle): Peaks early at ~0.60, then plummets to near 0.00 by step 100 and stays there.
**Bottom Row: Training Reward**
* **sync_interval = 20 (Bottom-Left Plot):**
* `REC-OneSide-NoIS (0.6, 2.0)` (Dark purple, +): Shows a noisy but clear upward trend, reaching near 1.0.
* `GRPO`, `REC-OneSide-NoIS (0.2)`, `REC-OneSide-IS (0.2)`: All trend upward with noise, ending between 0.75 and 0.90.
* `REINFORCE` (Light blue, circle): Reward collapses to near 0.00 after step 75, mirroring its accuracy crash.
* **sync_offset = 10 (Bottom-Middle Plot):**
* All algorithms except `REINFORCE` show strong, noisy upward trends, converging near 0.90-1.0 by step 150.
* `REINFORCE` (Light blue, circle): Shows a significant dip around step 60 but recovers to join the others near 0.90.
* **offline (Bottom-Right Plot):**
* All five algorithms show nearly identical, flat performance. The reward hovers around 0.5 with very minor fluctuations throughout all 150 steps. There is no clear upward trend for any method.
### Key Observations
1. **Algorithm Dominance:** `REC-OneSide-NoIS (0.6, 2.0)` is consistently the top or among the top performers in both accuracy and reward for the two synchronized conditions (`sync_interval`, `sync_offset`).
2. **REINFORCE Instability:** The `REINFORCE` algorithm is highly unstable in synchronized settings, suffering catastrophic performance drops. It performs comparably to others only in the `offline` setting for accuracy (until it crashes) and is flat in reward.
3. **Condition Impact:** The "offline" condition severely limits learning for all algorithms. Accuracy plateaus at a lower level (~0.5) or declines, and training reward shows no improvement over time, staying at ~0.5.
4. **Synchronization Benefit:** Both `sync_interval=20` and `sync_offset=10` enable clear learning progress for most algorithms, with `sync_offset=10` appearing to offer slightly more stability for `REINFORCE`.
5. **Performance Clustering:** The three `REC` variants and `GRPO` often perform similarly, forming a cluster below the top-performing `REC-OneSide-NoIS (0.6, 2.0)`.
### Interpretation
This set of charts demonstrates a comparative study of distributed or synchronized reinforcement learning algorithms. The data suggests that the proposed method, `REC-OneSide-NoIS (0.6, 2.0)`, is more robust and achieves higher final performance than the baselines (`REINFORCE`, `GRPO`) and its own ablated variants (`REC-OneSide-NoIS (0.2)`, `REC-OneSide-IS (0.2)`) under conditions with periodic synchronization (`sync_interval`, `sync_offset`).
The catastrophic failure of `REINFORCE` in synchronized settings highlights a known challenge of variance in policy gradient methods, which the `REC` methods appear to mitigate. The complete stagnation in the "offline" condition implies that without any synchronization or online interaction, the learning process for these particular tasks and algorithms fails to make progress, plateauing at a suboptimal reward level. The near-identical flat lines in the bottom-right plot are a strong visual indicator of this failure mode. The study underscores the critical importance of synchronization strategy and algorithmic stability in achieving effective learning.